这是一个科普性质的文章
之前很抗拒做 VFL,因为我认为 VFL 只是一个训练模型的工作。
但是,我刚刚意识到 VFL 不只是深度学习。(一种突然开窍的感觉)
实际上,垂直联邦学习 在 联邦学习 领域里,研究的核心是 Record Linkage / Data Integration。
这玩意被深度学习包装一下就变成了 VFL。
研究 HFL 的人比研究 VFL 的人多。因为 VFL 的数据太难获得了!
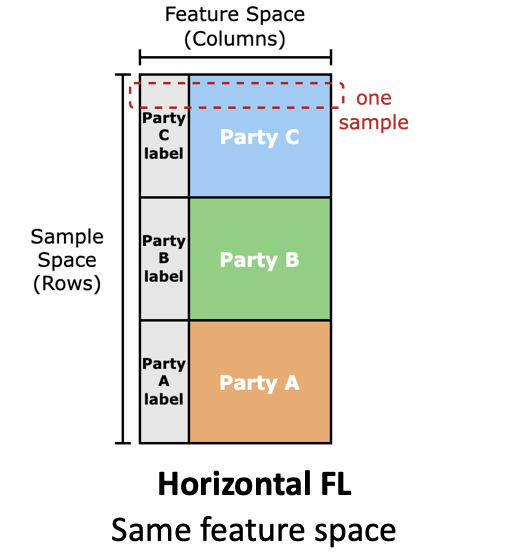
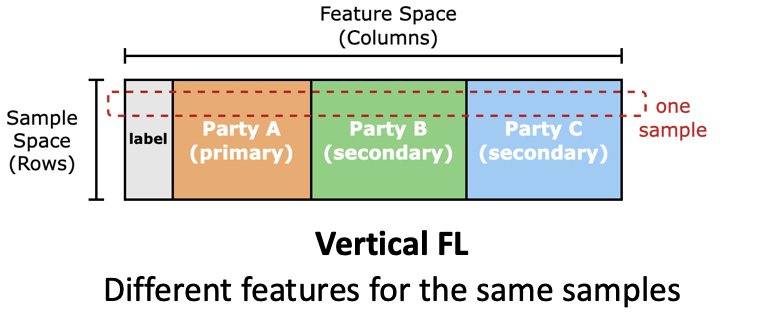
想想看,什么样的场景需要用到 VFL 呢?
比如银行和医院可以合作训练一个模型,预测用户的健康状态 / 还款能力。
训练这样一个模型之前,我们应该先把银行和医院的数据对齐一下(做一下 Record Linkage)。
Record Linkage: the process of identifying and linking records that correspond to the same individual across different databases.


在 Privacy Preserving 的情况下,如何做 Record Linkage 呢?
一个方法是 FedSim (NeurIPS2022),取 TopK 个最相关的 record 做 linkage ….
VFL 数据不够的情况下,我们怎么广泛评估算法好坏呢?
大部分研究者手动切分数据集,要么随机切,要么平均切,要么看心情切。
比如数据集有 16 个 feature,我分成 2 个 party,partyA 有 9 个 feature,partyB 有 7 个 feature。
直到 VertiBench (ICLR2024) 这篇工作,我们才有一个切分数据集的指导纲领(两个指标)。